Slowdown
So it’s midterm/final time so there hasn’t been any progress lately, dectection really needs to be fixed, I might just try using connected component labelling and retrieving areas although I can see an immediate problem bring if there isn’t a silent area around the maze it could just grab random large blobs.
Also I posted back on Oct31 a way to increase the speed was switching from using the get method of the matrix to just storing it in a integer array. After a class in CMPT 250 I realized that the reason the speed could’ve increase was because the get and set method could have been “thrashing my cache”.
Update Sept 17: 2013 So pretty much you just should never use an objects method for accessing data in my case using the put and get functions of the OpenCV Mat object to access individual pixel values. Rather converting it to some primitive data type or into a Bytebuffer will be many many times faster and more efficient. Function calls are bad!
It solves!
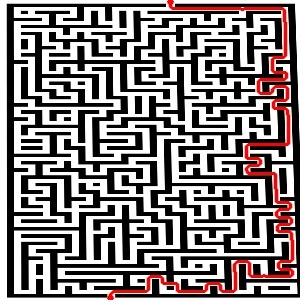
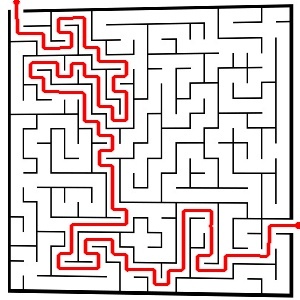
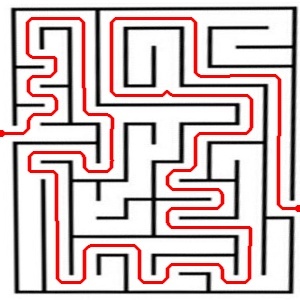
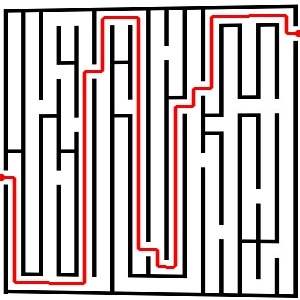
So it can now solve funky shaped mazes so long as the entrance and exit points lay on the outer most edges. Also that ridiculously big one took 116 seconds to solve.


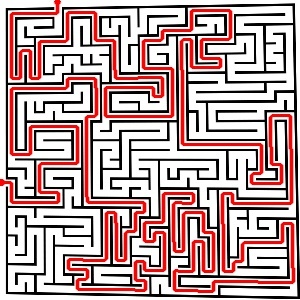
Homestretch
It’s so beautiful… All rectangular mazes can be solved and I should have no problem making it solve circular mazes or even mazes of weird shapes. The only thing left to do is now just some code cleanup, optimization and then port it over to the android. I’ll probably make a desktop version that will be able to solve rediculously large mazes.

Why do more when you can do less.
This has pretty much been my driving motivation, trying to optimize all my code to have the fastest runtime possible. Before when I was running ZS’s thinning algorithm I was reading straight from the Matrix using the CvMat get and put methods. I thought that maybe there was speed to be gained if before I converted my matrix into a two-dimentional integer array so I didn’t have to work with double values that the get and set methods provided. I’ll let the picture speak for itself.
The decrease was rediculous, and I still wonder; could it possibly be even optimized more? I’ll probably still play around with it and find out but I can definetly apply this to my A* algorithm.


